Questo articolo, per chi non l’avesse già notato dal titolo, è la seconda parte di un post precedente, che potremo sempre visitare a questo link, dove abbiamo spiegato cosa sia un bug hardware ed analizzato da vicino Meltdown (a cui molte testate hanno accennato in questo mese). Qui, continueremo il suddetto concentrandoci, però, su Spectre.
Come Meltdown, anche Spectre è un bug, o malfunzionamento, derivante da uno dei componenti fisici più importanti del nostro computer, ovvero dell’hardware, che è il processore o CPU. Mentre però Meltdown riguarda l’isolamento tra applicazioni ed utente e permette ad un programma di accedere alla cache o memoria di altri programmi o del sistema operativo, Spectre concerne la separazione tra diverse applicazioni e rispetto al primo risulta più pericoloso sebbene maggiormente difficile da sfruttare.
SPECTRE (CVE-2017-5753 e CVE-2017-5715)

Questo bug è stato trovato indipendentemente da due diverse persone: Jahn Horn (il quale si è occupato anche di Meltdown) e Paul Kocher in collaborazione Daniel Genkin, Mike Hamburg, Moritz Lipp e Yuval Yarom.
Al contrario di Meltdown che riguarda solamente le CPU dell’Intel, Spectre interessa tutti i processori moderni: ciò significa che tanto i computer fissi, come quelli portatili, che gli smartphone ed i tablet contengono questo bug. Il nome Spectre è stato scelto per due motivi principali: il primo è che esso si basa su quella che, come vedremo, viene chiamata speculative execution (esecuzione speculativa) e, secondariamente, perché ci perseguiterà per un bel po’ di tempo a causa delle difficoltà che si presentano nel correggere questo errore. Rispetto a Meltdown, già difficile da sfruttare, Spectre risulta ancora più complicato.
I processori moderni per velocizzare le proprie prestazioni utilizzano esecuzioni come l’out-of-order execution su cui si basa, come avevamo visto, Meltdown e, appunto, la speculative execution. Quest’ultima, che è quella che qui ci interessa, permette alla CPU di ipotizzare quale sarà la prossima esecuzione da processare e calcolarne in anticipo le possibili istruzioni. Ciò significa che un programma potrebbe essere eseguito in modo scorretto ma questi processori sono in grado di invertire l’errore tornando al loro stato precedente: prima di Spectre questa operazione era considerata sicura; questo bug, invece, ha dimostrato come in realtà tale operazione crei un serio problema nella sicurezza del proprio computer.
Un attacco che utilizzi Spectre (che, ricordiamoci, richiede comunque un alto livello di preparazione informatica) induce il processore ad eseguire delle sequenze di istruzioni ingannevoli (denominate transient instructions) che, però, verranno “resettate” dalla CPU che tornerà al proprio stato precedente “come da copione”. Il problema, però, emerge nel “come” e “quali” istruzioni ingannevoli inviate al processore vengono scelte poiché, se ben selezionate, potranno creare una fuoriuscita di informazioni proveniente dallo spazio degli indirizzi di memoria del pc della vittima.
A primo acchito questo potrebbe ricordare molto la tecnica utilizzata anche per Meltdown ma non è così. L’esecuzione speculativa utilizza la predizione delle diramazioni (branch prediction) che, invece, non pertiene all’out-of-order execution sfruttata da Meltdown: difatti, per quest’ultima ci si basa sull’osservazione di istruzioni da eseguire che, dopo un certo tempo, vengono interrotte perché impossibili da processare; mentre nel caso della speculative execution le istruzioni ingannevoli inviate da un malintenzionato verranno effettivamente processate creando un errore ed obbligando la CPU a tornare ad uno stato ad esse precedenti.
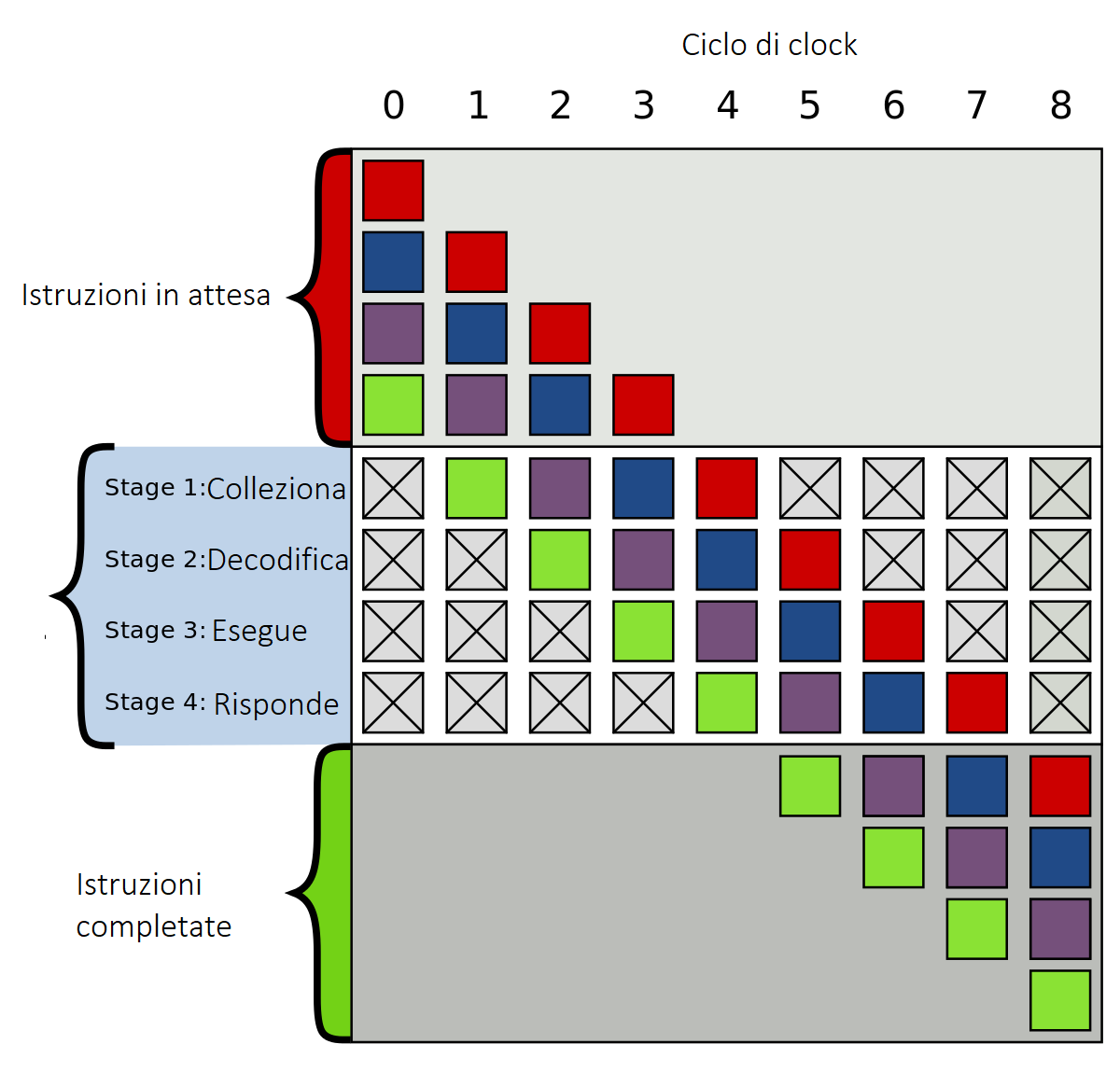 Qui a lato possiamo vedere la schematizzazione ed esemplificazione del funzionamento della predizione delle diramazioni appena denominata. I quattro colori (rosso, blu, viola, verde) rappresentano quattro diverse istruzioni in attesa ed indipendenti l’una dall’altra. Queste vengono eseguite parallelamente ed in contemporanea dal processore. Le istruzioni si muovono da un ciclo di clock ad un altro: al primo ciclo viene collezionata l’istruzione verde, al secondo tocca alla viola, al terzo la blu ed al quarto la rossa; al secondo ciclo l’istruzione verde viene decodificata, mentre al terzo tocca alla viola, al quarto alla blu ed al quinto alla rossa; e così via passando alla loro esecuzione ed alla risposta, fino ad arrivare al completamento delle stesse.
Qui a lato possiamo vedere la schematizzazione ed esemplificazione del funzionamento della predizione delle diramazioni appena denominata. I quattro colori (rosso, blu, viola, verde) rappresentano quattro diverse istruzioni in attesa ed indipendenti l’una dall’altra. Queste vengono eseguite parallelamente ed in contemporanea dal processore. Le istruzioni si muovono da un ciclo di clock ad un altro: al primo ciclo viene collezionata l’istruzione verde, al secondo tocca alla viola, al terzo la blu ed al quarto la rossa; al secondo ciclo l’istruzione verde viene decodificata, mentre al terzo tocca alla viola, al quarto alla blu ed al quinto alla rossa; e così via passando alla loro esecuzione ed alla risposta, fino ad arrivare al completamento delle stesse.
Per non complicare le idee abbiamo spiegato fin’ora la speculative execution come qualcosa di diverso dall’out-of-order execution sebbene, in realtà, la prima possa attivarsi e possa far parte della seconda: per esempio, il momento in cui l‘out-of-order execution arriva ad un’istruzione che richiede diverse condizioni il processore può provare a predire che tipo di operazione il processo necessiterà più tardi.
UN ESEMPIO D’USO DI SPECTRE: COME SFRUTTARE UN CONDITIONAL BRANCH
Il conditional branch può essere tradotto in italiano con diramazione condizionale. Questi viene chiamato in tal modo perché necessità di alcune condizioni per poter funzionare.
Un attacco di questo tipo cerca di portare la predizione delle diramazione verso una potenzialità, o soluzione, errata così da spingere il processore ad eseguire, via speculative execution, un’operazione che altrimenti non verrebbe calcolata e che porterà ad una fuoriuscita di informazioni.
Nel paper viene utilizzato un esempio di if-statement. Chi ha già alcune basi di programmazione dovrebbe sapere cosa sia l’if-statement (ne avevamo parlato in modo esteso in questo articolo dedicato al linguaggio C++) ma possiamo qui riassumerlo velocemente: questo tipo di dichiarazione crea due potenzialità, ovvero if (se) la prima affermazione è vera allora il programma la esegue, else (altrimenti) se la suddetta risulta falsa farà dell’altro.
Per prima cosa, un malintenzionato quindi inizierà ad inserire codici che implichino una dichiarazione che risulti sempre vera; tutto questo porterà il computer a decidere che se tutte le affermazioni fin’ora inserite sono vere allora anche la prossima che risulterà sicuramente vera. A questo punto, però, verrà inserito un nuovo codice con la variabile x contenente dei dati ingannevoli ed un valore che si trovi al di fuori di quelli legati all’array 1 la cui grandezza non è memorizzata nella cache. Sempre per chi non lo sapesse, l’array è un insieme di più elementi dello stesso tipo che ci permette di cambiare il numero degli stessi presenti al suo interno ed a cui è assegnato un indirizzo di memoria costante; la cache, invece, è quella che potremmo identificare con la memoria a breve termine del computer e che è necessaria il momento in cui devono essere processate delle informazioni.
Una volta inserito il valore di x, esso verrà comparato con gli elementi appartenenti all’array1: questo risulterà con un fallimento della cache rallentando il processore finché il valore non sarà disponibile sulla memoria DRAM (Dynamic Random Access Memory), ovvero la memoria dinamica ad accesso casuale. Mentre questo processo è in atto la speculative execution presuppone che la dichiarazione inserita sia vera aggiungendo x all’indirizzo costante dell’array1 e richiedendo dati alla memoria del sottosistema.
Con quanto detto poc’anzi quindi, guardiamo l’esempio di codice riportato sul paper è il seguente:
if (x < array1_size) y = array2[array1[x] * 256];
Quindi, con questo codice di cui abbiamo già spiegato la prima stringa, la CPU cercherà di predire i limiti segnalati siano veri; la speculative execution opererà sulla seconda stringa, ovvero array2[array1[x] * 256], usando la variabile x oramai “inquinata”. Una volta letta l’array2 i dati verranno caricati nella cache dipendente dall’array1[x] sempre usando il codice malevolo di x. Il momento in cui il processore nota l’errore della speculative execution, poiché i dati della DRAM sono arrivati, non è più possibile tornare indietro sebbene il registro venga riportato al suo stato iniziale: la lettura avvenuta su array2 influenzerà comunque lo stato della cache facendo dipendere l’indirizzo da un byte, chiamiamolo k, trovato in essa. Questo byte potrà essere quindi localizzato individuando il cambiamento nella cache del computer vittima. Così facendo, modificando ogni volta i valori di x e ripetendo questi passi, si potrà piano piano leggere la memoria del malcapitato pc.
Questo comunque è solo uno dei tanti esempi su come sia possibile sfruttare il bug di Spectre: un altro esempio potrebbe essere quello di “avvelenare” le diramazioni indirette, o indirect branches, che sono delle serie di istruzioni presenti a livello di linguaggio macchina; al contrario delle diramazioni dirette che specificano l’indirizzo della prossima istruzione da eseguire, in quelle indirette l’argomento individua dove tale indirizzo si trova permettendogli di saltare da più di due potenziali indirizzi: questo permetterebbe di riuscire a sfruttare il bug anche in assenza delle diramazioni condizionali di cui abbiamo parlato poc’anzi.
Inoltre, non dobbiamo dimenticare che sono necessari degli specifici codici (ci riferiamo al codice con valore x a cui abbiamo accennato nell’esempio fatto) che, tendenzialmente, risultano diversi per ogni tipo di processore: questo rende Spectre molto difficile e terribilmente dispendioso da utilizzare per un hacker qualsiasi lasciando il suo “studio” a Governi e grandi organizzazioni.
FONTI:
- https://meltdownattack.com/
- https://spectreattack.com/spectre.pdf
- https://googleprojectzero.blogspot.it/2018/01/reading-privileged-memory-with-side.html
- Intel Analysis of Speculative Execution Side Channels
- https://www.extremetech.com/computing/261792-what-is-speculative-execution
- Peter Bright, “Ars Technica”, What’s behind the Intel design flaw forcing numerous patches?, 3.01.2018
- Peter Bright, “Ars Technica”, “Meltdown” and “Spectre”: Every modern processor has unfixable security flaws, 4.01.2018
- Peter Bright, “Ars Technica”, Meltdown and Spectre: Here’s what Intel, Apple, Microsoft, others are doing about it, 5.01.2018
- HDBlog, Meltdown e Spectre: come risolvere e proteggersi contro potenziali exploit, 5.01.2018
- Samuel Gibbs, “The Guardian”, Meltdown and Spectre: ‘worst ever’ CPU bugs affect virtually all computers, 4.01.2018
- Andy Greenberg, “Wired”, A critical Intel flaw breaks basic security for most computers, 3.01.2018